GPT-5 will integrate the GPT and o-series, achieving unified multimodal and reasoning capabilities, including a main model (codename “nectarine” or “o3-alpha”), a mini version (codename “lobster”), and a nano version (codename “starfish”).
Insider sources claim GPT-5 will support a 1-million-token context window, MCP protocol, and parallel tool calling, with the mini version, Lobster, significantly enhancing programming capabilities, surpassing other models.
Liang Wenfeng Wins Top Award, DeepSeek R2’s Secret Weapon Revealed
DeepSeek and Peking University’s joint paper, Native Sparse Attention, won the ACL Best Paper Award, boosting model speed for long-text processing by 11 times.
This technology introduces a “native sparse attention” mechanism, shifting models from “fragmented stitching” to “organic integration,” greatly improving efficiency without sacrificing performance.
NSA technology has been fully pre-trained and validated on 27B and MoE architectures, using three reading strategies (compressed blocks, selective deep reading, sliding window) and gating mechanisms, serving as a core tech preview for DeepSeek R2.
Google Releases AlphaEarth Foundation Model: Building an “Earth ChatGPT”
Google DeepMind launched AlphaEarth Foundations, integrating diverse Earth observation data into a unified digital representation with 10-meter precision.
The system combines satellite imagery, radar scans, 3D laser mapping, and more, analyzing global land and nearshore areas in 10×10-meter grids, using only 1/16th the storage of similar AI systems.
Innovations include adaptive decoding architecture, spatially dense temporal bottlenecks, and precise geospatial-text alignment, already used by organizations like the UN FAO for custom map creation.
Moonvalley Launches Sketch-to-Video: Hand-Drawn Sketches to Movies
AI video generation company Moonvalley announced its flagship model, Marey, now supports Sketch-to-Video, allowing users to create cinematic videos from hand-drawn sketches with one click.
This feature extends Marey’s “hybrid creation” philosophy, aligning with directors’ visual workflows, supporting character motion or camera path definitions for coherent video generation.
Currently supports 1080p@24fps output, available to Marey platform subscribers starting at $14.99/month, with pay-per-use rendering credits also available.
Ollama Finally Launches Chat Interface, No More Command Lines
Ollama 0.10.1 introduces a visual graphical interface for Mac and Windows, lowering the barrier for non-technical users.
The new version offers a chat interface, supporting model downloads, PDF/document conversations, multimodal interactions, and document writing features.
A new multimodal engine allows sending images to large language models, provided the model supports multimodality, such as Gemma 3 and Qwen2.5vl.
Report Insights
Zuckerberg’s Open Letter: Superintelligence Vision and Meta’s Open-Source Policy Shift
Meta CEO Zuckerberg published an open letter stating that AI systems are showing signs of self-improvement, with superintelligence development imminent. Meta aims to build personal superintelligence.
The letter reveals Meta is adjusting its AI model release strategy. While superintelligence benefits should be shared globally, Meta will “carefully consider what to open-source,” suggesting not all Llama models will remain fully open-source.
Meta’s Q2 earnings report announced up to $72 billion for AI infrastructure in 2025, boosting its stock price by 10% in after-hours trading.
a16z: AI is Rewriting Investment Criteria, Platform Competition Hinges on Three Factors
a16z partner Martin Casado believes AI investment now focuses on platforms’ ability to deliver consistent business outcomes, shifting product value from “functional tools” to “outcome-driven services.”
Platform competition hinges on three factors: organizational model, resource allocation, and product strategy. Governance efficiency and product capability are equally critical, requiring “modular development × rapid response mechanisms × clear commercialization paths.”
AI valuation logic focuses on specific scenarios, analyzed through pessimistic, neutral, and optimistic simulations, with key catalysts like customer acquisition pace and infrastructure deployment speed.
OpenAI introduces “Study Mode” for ChatGPT, using a Socratic step-by-step guidance approach to help users understand complex concepts deeply.
Available for free to all Free, Plus, Pro, and Team plan users, featuring interactive prompts, step-by-step solutions, and personalized support.
The mode’s prompt was discovered and shared by developer Simon Willison, revealing that the system adapts teaching strategies based on users’ educational background and knowledge base.
Grok to Launch “Imagine” Video Feature, Challenging Google’s Veo 3
Testing shows realistic results with rich details, supporting various styles, and allowing creation via voice or text descriptions.
Imagine will have a dedicated tab, offering near-real-time image generation and preset modes like Spicy, Fun, and Normal, directly competing with Google’s Veo 3.
Kunlun Tech Open-Sources GPT-4o-like Multimodal Model Skywork UniPic
Kunlun Tech open-sources Skywork UniPic, a multimodal unified model with just 1.5B parameters, achieving performance comparable to specialized models with tens of billions of parameters, running smoothly on consumer-grade GPUs.
The model uses an autoregressive architecture, deeply integrating image understanding, text-to-image generation, and image editing, similar to GPT-4o’s technical approach.
Through high-quality small-data training, progressive multitask training, and a proprietary reward model, UniPic achieves state-of-the-art (SOTA) performance on benchmarks like GenEval and DPG-Bench.
Image Editing Model SeedEdit 3.0 Enables Photo Editing via Dialogue
Volcano Engine releases SeedEdit 3.0, integrated into VolcanoArk, focusing on instruction following, subject preservation, and generation quality control.
The model supports image editing tasks like removal, replacement, and style transfer via natural language instructions, matching GPT-4o and Gemini 2.5 Pro in scenarios like text modification and background replacement.
Built on the Seedream 3.0 text-to-image model, it uses multistage training and adaptive timestep sampling to achieve 8x inference acceleration, reducing runtime from 64 seconds to 8 seconds.
NotebookLM Introduces Video Overviews Feature
Google updates its AI note-taking tool NotebookLM with a “Video Overviews” feature, automatically generating structured videos from uploaded notes, PDFs, and images.
Users can customize video content based on learning topics, knowledge levels, and goals, enhancing personalized learning experiences.
Now available to all English users, NotebookLM’s Studio panel is upgraded to save multiple output versions in one notebook, with four new shortcut buttons for audio, video, mind maps, and reports.
Frontier Technology
Former Google CEO Schmidt: “Open Weights” Key to China’s Rapid AI Development
At the WAIC conference, former Google CEO Eric Schmidt noted China’s significant AI progress in two years, with models like DeepSeek, Mini Max, and Kimi reaching global leadership.
Schmidt highlighted China’s “open weights” strategy as a key differentiator from the U.S., driving rapid AI development.
He advocated for stronger U.S.-China AI cooperation, emphasizing open dialogue and trust-building to address AI misuse risks and ensure human safety and dignity as shared goals.
Claude Introduces Weekly Usage Limits, $200 Plan Costs Users Thousands
Anthropic announced weekly usage limits for Claude Pro and Max users starting late August, affecting less than 5% of subscribers.
Some users ran Claude Code 24/7, with extreme cases seeing a $200 plan incur tens of thousands in costs.
Users report a lack of transparency in usage data, unable to track consumed tokens or remaining quotas, prompting many to seek alternative products.
Microsoft Edge Browser Transforms into an AI Agent
Edge introduces “Copilot Mode,” enabling cross-tab contextual awareness to analyze all open pages simultaneously.
A streamlined interface with a unified input box auto-detects user intent, supporting voice control and thematic journey features.
Currently free in all Copilot markets, this feature may later be bundled with Copilot subscriptions, potentially ending Edge’s free software status.
MIRIX: Open-Source Multimodal, Multi-Agent AI Memory System
Researchers from UC San Diego and NYU launched and open-sourced MIRIX, the world’s first multimodal, multi-agent AI memory system, with a desktop app.
MIRIX divides memory into six modules—core, contextual, semantic, procedural, resource, and knowledge vault—managed by a meta-memory controller and six sub-modules.
In ScreenshotVQA tests, MIRIX outperforms traditional RAG by 35% in accuracy with 99.9% less storage; it achieves a record-breaking 85.4% on the LOCOMO long-conversation task.
Frontier Technology
World’s Most Accurate Solar Storm Prediction: First Chain-Based AI Space Weather Model
The model pioneers a chain-training structure with three components: solar wind (“Xufeng”), Earth’s magnetic field (“Tianci”), and ionosphere (“Dianqiong”).
Fengyu achieves ~10% error in global electron density predictions, excelling in major geomagnetic storm events, with 11 Chinese national invention patents filed.
Shanghai AI Lab Open-Sources Intern-S1, a Multimodal Scientific Model
Shanghai AI Lab released and open-sourced Intern-S1, the top globally open-sourced multimodal model, surpassing closed-source Grok-4 in scientific capabilities.
Features a “cross-modal scientific parsing engine” for precise interpretation of chemical formulas, protein structures, seismic signals, and more.
The team’s unified-specialized data synthesis method delivers strong general reasoning and top-tier specialized capabilities, significantly reducing reinforcement learning costs.
Report Insights
a16z Partner: No Technical Moat, Future Lies in Infrastructure and Vertical Focus
a16z’sMartin Casado predicts AI model competition will mirror cloud computing’s oligopoly, forming a new brand-driven landscape.
The application layer lacks a technical moat; rational business strategies involve “sacrificing profits for distribution,” with value emerging from model infrastructure and vertical specialization.
AI doesn’t turn average developers into super engineers but makes “10x engineers 2x better” by eliminating platform complexities, refocusing programming on creative essence.
Hundredfold Boost in Modeling Efficiency, Revolutionizing Productivity in Gaming and Digital Twins
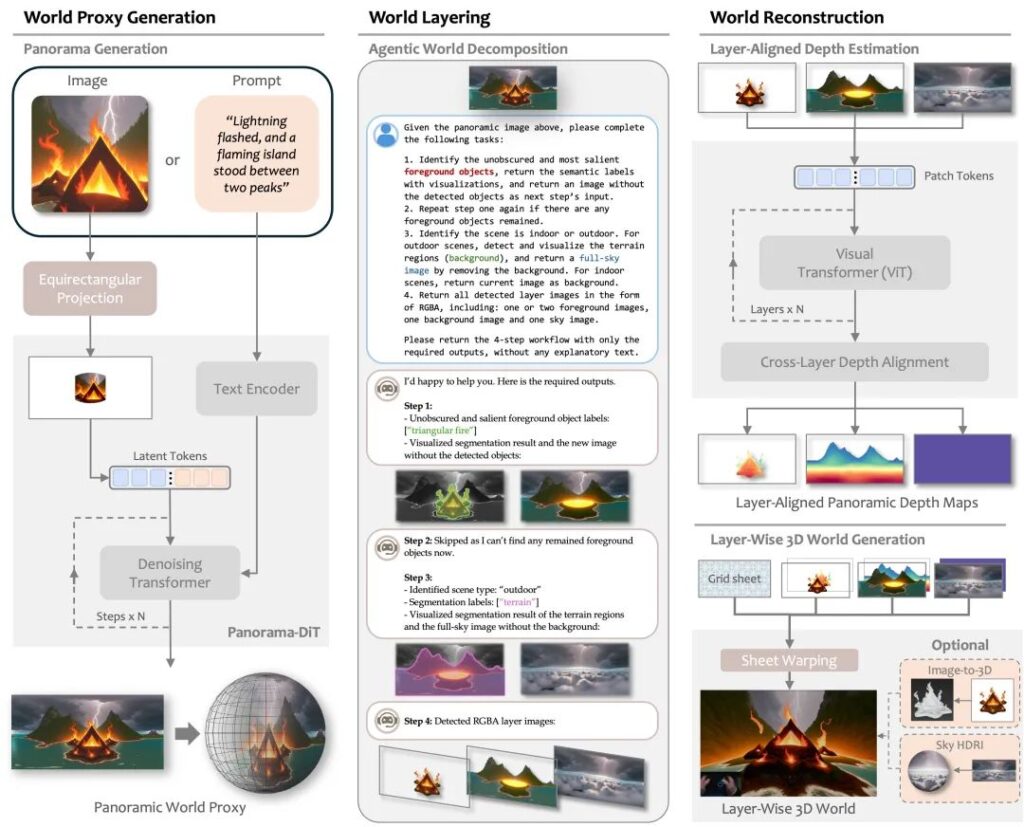
I. What is the Hunyuan 3D World Model?
On July 27, 2025, at the World Artificial Intelligence Conference (WAIC), Tencent officially launched and open-sourced the Hunyuan 3D World Model 1.0, the industry’s first open-source world generation model supporting immersive exploration, interaction, and simulation. As part of Tencent’s Hunyuan large-scale model family, this model aims to fundamentally transform 3D content creation.Traditional 3D scene construction requires professional teams and weeks of effort. In contrast, the Hunyuan 3D World Model can generate fully navigable, editable 3D virtual scenes in just minutes using a single text description or an image. Its core mission is to address the high barriers and low efficiency of digital content creation, meeting critical needs in fields like game development, VR experiences, and digital twins.Tencent introduced its “1+3+N” AI application framework to the public for the first time, with the Hunyuan large-scale model as the core engine and the 3D World Model as a key component of its multimodal capability matrix. Tencent Vice President Cai Guangzhong emphasized at the conference: “AI is still in its early stages. We need to push technological breakthroughs into practical applications, bringing user-friendly AI closer to users and industries.”
II. What Can the Hunyuan 3D World Model Do?
Zero-Barrier 3D Scene Generation
Text-to-World: Input “a cyberpunk city in a rainy night with glowing neon hovercar lanes,” and the model generates a complete scene with buildings, vegetation, and dynamic weather systems.
Image-to-World: Upload a sketch or photo to create an interactive 3D space, seamlessly compatible with VR devices like Vision Pro.
Industrial-Grade Creation Tools
Outputs standardized Mesh assets, directly compatible with Unity, Unreal Engine, Blender, and other mainstream tools.
Supports layered editing: independently adjust foreground objects, swap sky backgrounds, or modify material textures.
Built-in physics simulation engine automatically generates dynamic effects like raindrop collisions and light reflections.
Revolutionary Efficiency Gains
Game scene creation reduced from 3 weeks to a 30-minute draft plus a few hours of fine-tuning.
Modeling labor costs cut by over 60%, enabling small teams to rapidly prototype ideas.
III. Technical Principles of the Hunyuan 3D World Model
The model’s breakthrough lies in its “semantic hierarchical 3D scene representation and generation algorithm”:
Intelligent Scene Decomposition Complex 3D worlds are broken down into semantic layers (e.g., sky/ground, buildings/vegetation, static/dynamic elements), enabling separate generation and recombination of elements. This layered approach ensures precise understanding of complex instructions like “a medieval castle with a flowing moat.”
Dual-Modality Driven
Text-to-World: Multimodal alignment technology maps text descriptions to structured 3D spatial parameters.
Image-to-World: Uses panoramic visual generation and layered 3D reconstruction to infer depth from 2D images.
Physics-Aware Integration While generating geometric models, the algorithm automatically assigns physical properties (e.g., gravity coefficients, material elasticity), making scenes not only viewable but also physically interactive.
Compared to traditional 3D generation models, this technology ranks first in Chinese-language understanding and scene restoration on the LMArena Vision leaderboard, with aesthetic quality surpassing mainstream open-source models by over 30%.
IV. Application Scenarios
Game Industry Transformation
Rapid Prototyping: Generate base scenes, allowing developers to focus on core gameplay mechanics.
Dynamic Level Generation: Create new maps in real-time based on player behavior, such as random dungeons in RPGs.
Digital Twin Applications
Factory Simulation: Upload production line photos to generate virtual factories for testing robot path planning.
Architectural Visualization: Convert CAD drawings into navigable showrooms with real-time material adjustments.
Inclusive Creation Ecosystem
Education: Students can generate 3D battlefields from history textbooks for immersive strategy learning.
Personal Creation: Parents can turn children’s doodles into interactive fairy-tale worlds, building family-exclusive metaverses.
Robot Training
Integrated with Tencent’s Tairos embodied intelligence platform, generated scenes train service robots for household tasks.
V. Demo ExamplesOfficial Showcases:
Futuristic City Generation: Input “a neon-lit floating city after rain,” creating a 3D streetscape with holographic billboards, flying cars, and dynamic rain reflections.
Natural Scene Creation: Upload a forest photo to generate an explorable 3D jungle, where users can remove trees, add tents, and modify layouts in real-time.
Industry Test Results:
A game studio used the prompt “fantasy elf village” to generate a base scene, adjusted architectural styles, and reduced development time by 70%.
VI. Conclusion
The open-sourcing of the Hunyuan 3D World Model marks a shift in 3D content creation from professional studios to the masses. When a single spoken phrase can generate an interactive virtual world, the boundaries of digital creation are shattered. Tencent’s move not only equips developers with powerful tools but also builds the 3D content infrastructure for the AI era—much like Android reshaped the mobile ecosystem, 3D generation technology is now a cornerstone for the metaverse.With the upcoming open-source release of lightweight 0.5B-7B models for edge devices by month’s end, this technology will reach phones and XR glasses. As creation barriers vanish, anyone can become a dream-weaver of virtual worlds, ushering in a new era of digital productivity.
Following last week’s trio of AI releases, Alibaba has unveiled another groundbreaking open-source model: the cinematic video generation model Tongyi Wanxiang Wan2.2, optimized for AI video generation and AI video generator applications. Wan2.2 integrates three core cinematic aesthetic elements—lighting, color, and camera language—into the model, offering over 60 intuitive, controllable parameters to significantly enhance the efficiency of producing movie-quality visuals.
Currently, the model can generate 5-second high-definition videos in a single run, with users able to create short films through multi-round prompts. In the future, Tongyi Wanxiang aims to extend the duration of single video generations, making AI video creation even more efficient.
Wan2.2 introduces three open-source models: Text-to-Video (Wan2.2-T2V-A14B), Image-to-Video (Wan2.2-I2V-A14B), and Unified Video Generation (Wan2.2-TI2V-5B). The Text-to-Video and Image-to-Video models are the industry’s first to leverage the Mixture of Experts (MoE) architecture for AI video generation, with a total of 27 billion parameters and 14 billion active parameters. These models consist of high-noise and low-noise expert models, handling overall video layout and fine details, respectively. This approach reduces computational resource consumption by approximately 50% compared to models of similar scale, effectively addressing the issue of excessive token processing in AI video generators. It also achieves significant improvements in complex motion generation, character interactions, aesthetic expression, and dynamic scenes.
Moreover, Wan2.2 pioneers a cinematic aesthetic control system, delivering professional-grade capabilities in lighting, color, composition, and micro-expressions. For instance, by inputting keywords like “twilight,” “soft light,” “rim light,” “warm tones,” or “centered composition,” the model can automatically generate romantic scenes with golden sunset hues. Alternatively, combining “cool tones,” “hard light,” “balanced composition,” and “low angle” produces visuals akin to sci-fi films, showcasing its versatility for AI video creation and AI video generation tasks.
Flux Kontext is a cutting-edge AI image generation and editing model developed by Black Forest Labs. It supports text-to-image generation, image-to-image transformation, and precise image editing through detailed text prompts. As one of the leading image generation technologies available today, Flux Kontext stands out for its exceptional performance and versatile applications. This article will explore the capabilities, usage, and key application scenarios of the Flux Kontext series.
and the open-source FLUX.1 Kontext [dev] (non-commercial use only).
Max Version: Delivers top-tier performance, ideal for users seeking the ultimate in quality.
Pro Version: Offers excellent performance with great value, recommended for broad use.
Dev Version: An open-source option for developers to explore, but not for commercial purposes.
1. Text-to-Image Generation
Similar to most image generation models, Flux Kontext enables the creation of high-quality images from text prompts. Simply input a detailed descriptive prompt to generate images that align with your creative vision.
2. Image Editing
The standout feature of Flux Kontext is its powerful image editing capabilities. By combining image inputs with text prompts, users can precisely modify images with results that exceed expectations. Diverse application scenarios are showcased below.
3. Text Generation Capability
Traditional image generation models often struggle with text rendering, producing blurry or illegible text. Flux Kontext breaks through this limitation, generating clear and impressive English text within images.
Application Scenarios for Flux Kontext
Below are selected use cases and examples demonstrating Flux Kontext’s versatility:
Image Filters Upload a selfie and input the prompt: “Transform the image into Ghibli style.”
AI Headshot Generation Upload a photo and input the prompt: “Create a formal professional headshot, wearing a suit and tie.”
Background Replacement Upload a photo and input the prompt: “Replace the background with the Eiffel Tower, with me standing beneath it.”
Change Hairstyle Upload a photo and input the prompt: “Change my hairstyle to short red hair.”
Change Clothing Upload a photo and input the prompt: “Replace the clothing with a suit and tie.”
Old Photo Restoration Upload an old photo and input the prompt: “Restore the photo and enhance it to ultra-high definition while preserving the original content.”
Product Background Modification Ideal for e-commerce, upload a product image and input the prompt: “Replace the background with an ocean scene.”
Product Model Replacement Upload a product image and input the prompt: “A female model holding the product, smiling at the camera.”
Relighting Upload an image and input the prompt: “Set the background to a dark indoor setting with blue-purple gradient lighting from the right.”
Add Text Upload an image and input the prompt: “Add cursive text ‘I Love Fotol AI’ on the clothing.”
Modify Text Upload an image with text and input the prompt: “Change the text ‘Fotol AI’ to ‘Flux’.”
Remove Watermark Upload an image with a watermark and input the prompt: “Remove all watermarks from the image.”
Usage Tips
Iterate for Optimal Results Generative AI may not meet your expectations on the first try. If unsatisfied, adjust the prompt or regenerate the image multiple times.
Use Detailed and Specific Prompts For precise editing, provide detailed prompts. For example, instead of “Remove the apple on the left,” specify “Remove the apple in the bottom-left corner.”
Use Quotation Marks for Text Modifications When editing text, enclose the target text in quotation marks, e.g., “Change the text ‘Fotol AI’ to ‘Flux’.”
Using Flux Kontext on the Fotol AI Platform
Fotol AI is a comprehensive platform integrating cutting-edge AI technologies, including AI image generation, video generation, voice generation, and music generation, all accessible without switching platforms. Through links @flux-kontext-pro or @flux-kontext-max, you can directly access the Flux Kontext series. Fotol AI’s Context Mode automatically attaches the most recently generated file, eliminating the need for repetitive uploads and significantly enhancing the efficiency of using AI technologies like Flux Kontext.
Conclusion
Flux Kontext, with its powerful image generation and editing capabilities, unlocks infinite possibilities for personal creativity, commercial applications, and artistic creation. Whether crafting stunning artworks or optimizing product displays for e-commerce, Flux Kontext delivers efficient and precise results. Paired with the seamless experience of the Fotol AI platform, Flux Kontext is undeniably a game-changer in today’s image generation landscape. Try it now and unleash your creativity!
We are thrilled to introduce Fotol AI—a next-generation platform that seamlessly integrates the most advanced AI technologies into a single, unified hub. From AI-powered image and video generation to music generation, 3D asset creation, text-to-speech (TTS), and the latest large language models (LLMs), Fotol AI eliminates the need for multiple subscriptions. With our intuitive, standardized interface, you can harness the full potential of AI—without the learning curve.
Why Fotol AI?
1. All-in-One AI Powerhouse
No more juggling between platforms. Fotol AI continuously integrates state-of-the-art AI models, including:
With hundreds of AI technologies at your fingertips, Fotol AI is your ultimate productivity multiplier.
2. Unified Experience, Zero Learning Curve
We’ve redefined AI accessibility with a consistent, user-friendly interface across all tools. Whether you’re generating images, editing videos, or crafting 3D assets, the workflow remains familiar—no relearning required.
3. Effortless Workflow Integration
Example: Need to turn an AI-generated image into a video?
Fotol AI isn’t just another tool—it’s the future of AI-powered productivity. Whether you’re an individual, entrepreneur, or creative professional, unlock the full potential of AI with one platform, one workflow, and zero barriers.