Generative AI
Claude Introduces Weekly Usage Limits, $200 Plan Costs Users Thousands
- Anthropic announced weekly usage limits for Claude Pro and Max users starting late August, affecting less than 5% of subscribers.
- Some users ran Claude Code 24/7, with extreme cases seeing a $200 plan incur tens of thousands in costs.
- Users report a lack of transparency in usage data, unable to track consumed tokens or remaining quotas, prompting many to seek alternative products.
Microsoft Edge Browser Transforms into an AI Agent
- Edge introduces “Copilot Mode,” enabling cross-tab contextual awareness to analyze all open pages simultaneously.
- A streamlined interface with a unified input box auto-detects user intent, supporting voice control and thematic journey features.
- Currently free in all Copilot markets, this feature may later be bundled with Copilot subscriptions, potentially ending Edge’s free software status.
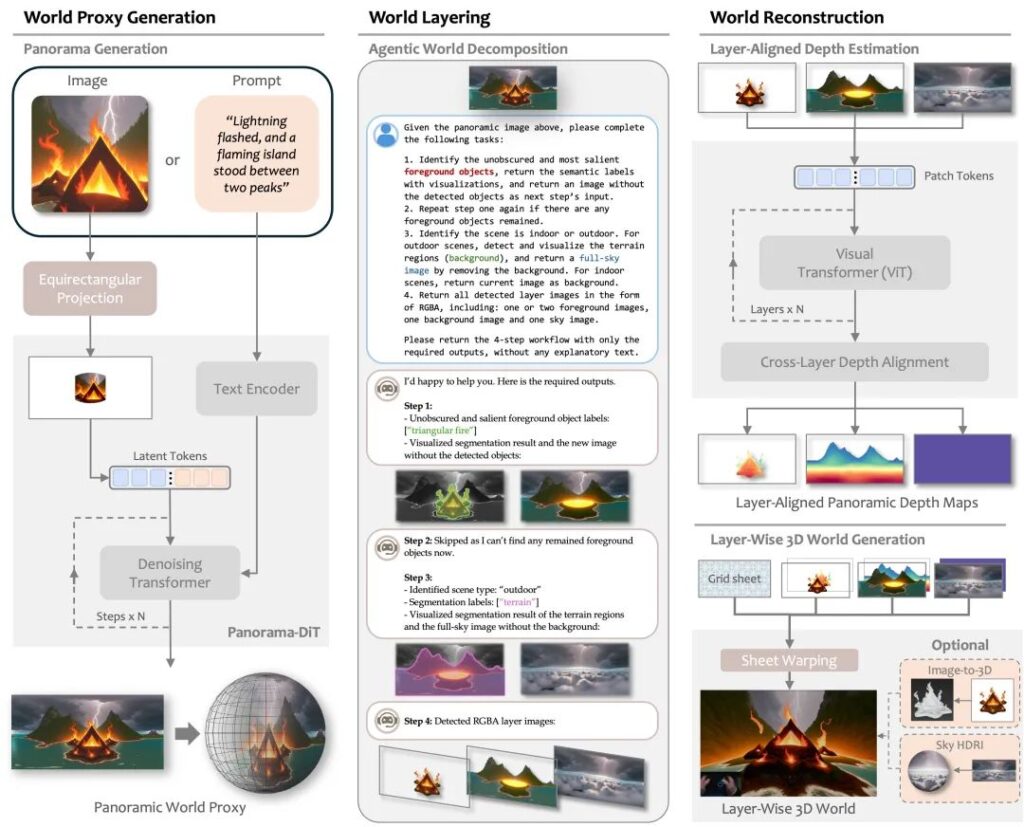
MIRIX: Open-Source Multimodal, Multi-Agent AI Memory System

- Researchers from UC San Diego and NYU launched and open-sourced MIRIX, the world’s first multimodal, multi-agent AI memory system, with a desktop app.
- MIRIX divides memory into six modules—core, contextual, semantic, procedural, resource, and knowledge vault—managed by a meta-memory controller and six sub-modules.
- In ScreenshotVQA tests, MIRIX outperforms traditional RAG by 35% in accuracy with 99.9% less storage; it achieves a record-breaking 85.4% on the LOCOMO long-conversation task.
Frontier Technology
World’s Most Accurate Solar Storm Prediction: First Chain-Based AI Space Weather Model
- China’s National Satellite Meteorological Center, Nanchang University, and Huawei released “Fengyu,” the world’s first chain-based AI space weather forecasting model.
- The model pioneers a chain-training structure with three components: solar wind (“Xufeng”), Earth’s magnetic field (“Tianci”), and ionosphere (“Dianqiong”).
- Fengyu achieves ~10% error in global electron density predictions, excelling in major geomagnetic storm events, with 11 Chinese national invention patents filed.
Shanghai AI Lab Open-Sources Intern-S1, a Multimodal Scientific Model
- Shanghai AI Lab released and open-sourced Intern-S1, the top globally open-sourced multimodal model, surpassing closed-source Grok-4 in scientific capabilities.
- Features a “cross-modal scientific parsing engine” for precise interpretation of chemical formulas, protein structures, seismic signals, and more.
- The team’s unified-specialized data synthesis method delivers strong general reasoning and top-tier specialized capabilities, significantly reducing reinforcement learning costs.
Report Insights
a16z Partner: No Technical Moat, Future Lies in Infrastructure and Vertical Focus
- a16z’s Martin Casado predicts AI model competition will mirror cloud computing’s oligopoly, forming a new brand-driven landscape.
- The application layer lacks a technical moat; rational business strategies involve “sacrificing profits for distribution,” with value emerging from model infrastructure and vertical specialization.
- AI doesn’t turn average developers into super engineers but makes “10x engineers 2x better” by eliminating platform complexities, refocusing programming on creative essence.