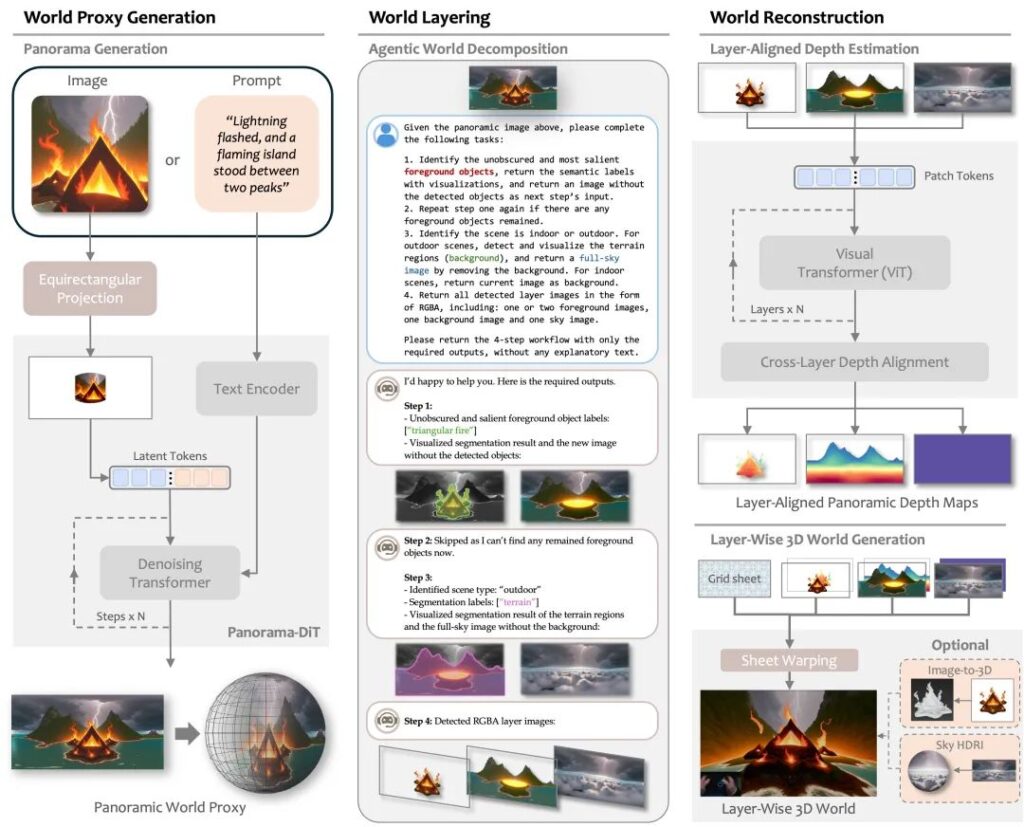
Generative AI
Rumored GPT-5 Leak! Unified Dual Series, Programming Demo Exposed
- Many users have spotted GPT-5 traces on ChatGPT, MacOS apps, Cursor, Microsoft Copilot, and OpenAI API platforms, with a potential release as early as next week.
- GPT-5 will integrate the GPT and o-series, achieving unified multimodal and reasoning capabilities, including a main model (codename “nectarine” or “o3-alpha”), a mini version (codename “lobster”), and a nano version (codename “starfish”).
- Insider sources claim GPT-5 will support a 1-million-token context window, MCP protocol, and parallel tool calling, with the mini version, Lobster, significantly enhancing programming capabilities, surpassing other models.
Liang Wenfeng Wins Top Award, DeepSeek R2’s Secret Weapon Revealed
- DeepSeek and Peking University’s joint paper, Native Sparse Attention, won the ACL Best Paper Award, boosting model speed for long-text processing by 11 times.
- This technology introduces a “native sparse attention” mechanism, shifting models from “fragmented stitching” to “organic integration,” greatly improving efficiency without sacrificing performance.
- NSA technology has been fully pre-trained and validated on 27B and MoE architectures, using three reading strategies (compressed blocks, selective deep reading, sliding window) and gating mechanisms, serving as a core tech preview for DeepSeek R2.
Google Releases AlphaEarth Foundation Model: Building an “Earth ChatGPT”
- Google DeepMind launched AlphaEarth Foundations, integrating diverse Earth observation data into a unified digital representation with 10-meter precision.
- The system combines satellite imagery, radar scans, 3D laser mapping, and more, analyzing global land and nearshore areas in 10×10-meter grids, using only 1/16th the storage of similar AI systems.
- Innovations include adaptive decoding architecture, spatially dense temporal bottlenecks, and precise geospatial-text alignment, already used by organizations like the UN FAO for custom map creation.
Moonvalley Launches Sketch-to-Video: Hand-Drawn Sketches to Movies
- AI video generation company Moonvalley announced its flagship model, Marey, now supports Sketch-to-Video, allowing users to create cinematic videos from hand-drawn sketches with one click.
- This feature extends Marey’s “hybrid creation” philosophy, aligning with directors’ visual workflows, supporting character motion or camera path definitions for coherent video generation.
- Currently supports 1080p@24fps output, available to Marey platform subscribers starting at $14.99/month, with pay-per-use rendering credits also available.
Ollama Finally Launches Chat Interface, No More Command Lines
- Ollama 0.10.1 introduces a visual graphical interface for Mac and Windows, lowering the barrier for non-technical users.
- The new version offers a chat interface, supporting model downloads, PDF/document conversations, multimodal interactions, and document writing features.
- A new multimodal engine allows sending images to large language models, provided the model supports multimodality, such as Gemma 3 and Qwen2.5vl.
Report Insights
Zuckerberg’s Open Letter: Superintelligence Vision and Meta’s Open-Source Policy Shift
- Meta CEO Zuckerberg published an open letter stating that AI systems are showing signs of self-improvement, with superintelligence development imminent. Meta aims to build personal superintelligence.
- The letter reveals Meta is adjusting its AI model release strategy. While superintelligence benefits should be shared globally, Meta will “carefully consider what to open-source,” suggesting not all Llama models will remain fully open-source.
- Meta’s Q2 earnings report announced up to $72 billion for AI infrastructure in 2025, boosting its stock price by 10% in after-hours trading.
a16z: AI is Rewriting Investment Criteria, Platform Competition Hinges on Three Factors
- a16z partner Martin Casado believes AI investment now focuses on platforms’ ability to deliver consistent business outcomes, shifting product value from “functional tools” to “outcome-driven services.”
- Platform competition hinges on three factors: organizational model, resource allocation, and product strategy. Governance efficiency and product capability are equally critical, requiring “modular development × rapid response mechanisms × clear commercialization paths.”
- AI valuation logic focuses on specific scenarios, analyzed through pessimistic, neutral, and optimistic simulations, with key catalysts like customer acquisition pace and infrastructure deployment speed.